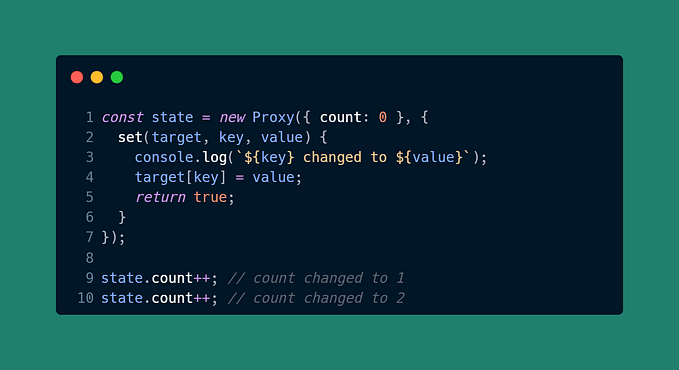
Storing Pandas dataframes efficiently in Python
Introduction
If you are into solving data science and / or machine learning problems using Python you have probably come across Pandas, one of the most common data analysis and manipulation packages for Python.
Pandas stores data in a form called DataFrame, which is a 2 dimensional data structure (like a 2-D array) that can contain data in various formats (numerical data, categorical variables, etc).
So here are some tips to store date in dataframes ina more efficient way that will improve both memory and running time performance.
Tip #1: Cast categorical variables
Suppose we fill a pandas column called color with 1000 values which are randomly picked by an array containing 6 distinct values ('WHITE', 'BLACK', 'RED', 'YELLOW', 'BLUE' and 'GREEN').
This column now contains a categorical variable as it can only take discrete and values from a finite set. Pandas by default will store this kind of columns as type object.
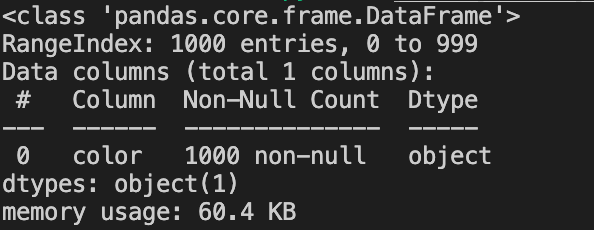
The following code will print the datatypes of the column we just defined as well as the ‘memory footprint’ of the dataframe.
After running the code above, we receive the results shown in the following screenshot. Pandas assigned to the column the data type object by default and the column uses around 60.4 KB of memory.
Now let’s try to cast this column to a data type called category and print once again the memory footprint of the data frame.
We run the code again and we see the following results.
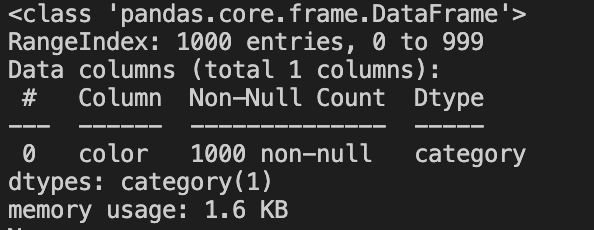
Whaaaaaat ? It seems that surprisingly, with this simple change we managed to reduce the size of our data frame in memory by about 97%.
This is because pandas treat categorical values more efficiently that generic values because by declaring them as categorical it knows that they are discrete and can only take certain values.
However, there is no guarantee of the amount of reduction in memory footprint as the major factor that influences this optimization is the cardinality of the variable that we treat.
Note: Cardinality is the number of distinct values that a categorical variable can take (in our example, the variable color can take only 6 different values, thus it has a cardinality of 6).
As a rule of thumb, you can safely assume that the lower the cardinality of a categorical variable, the highest the reduction of the memory footprint using the method demonstrated above.
Tip #2: Cast variables to bool (special case of Tip #1)
Many times in a dataset we may find “categorical” columns that take only 2 discrete values, like ‘YES’ and ‘NO’ or ‘male’ and ‘female’ and by default these values will be treated as objects by pandas. So this tip is about a special case of the first tip. But this time, we will not cast these values to category but we will map them to boolean values (True / False). As I see no value in running the maths again for this case, I am sure you can understand that this move will have a major positive impact in the memory footprint of a column with the characteristic mentioned above.
So, assuming that the column with the string values is called coin_toss and that this column only contains the values HEAD and TAILS , we can cast the column to boolean using the code shown below.
Tip #3: Downcast integers when possible
Now suppose we want to save in a column of a pandas dataframe, the ages of 1000 persons. We will fill the column by randomly selecting integers in the range [0,120] (as age is always non-negative and it is highly improbable to observe values greater than 120 in this context).
The following snippet does all the things described above, then prints the datatype of the column and the memory footprint of the dataset.
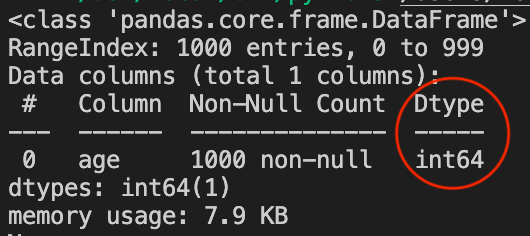
When we run the code, we observe that by default pandas selected int64 as the data type for this column and the column has a total memory footprint of around 7.9KB.
At this point let’s remember that the int64 data type can store up to 2⁶⁴ distinct values while we only need to store 120 values (< 2⁸) , which can be safely stored to an 8-bit integer. This practically means, that around 64 — 8 = 56 bits per row will be completely useless in our scenario. As you probably understand this is a HUGE waste of memory and now we will see how we can avoid it.
Now we will downcast this column to int8 and print once again the memory footprint of the data frame.
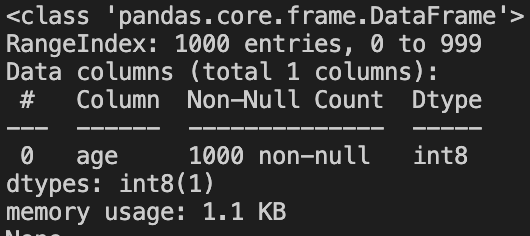
Yayyy! By downcasting the column to int8 we managed to reduce the memory footprint to almost 1/8 of the previous setup.
Conclusion
Being both the storage and data manipulation layer of many python applications, correct and efficient usage of pandas dataframes has a significant role in the performance of a modern software solution. As demonstrated in this article, small optimizations that can be implemented easily and in a safe and robust manner can improve the overall performance substantially.